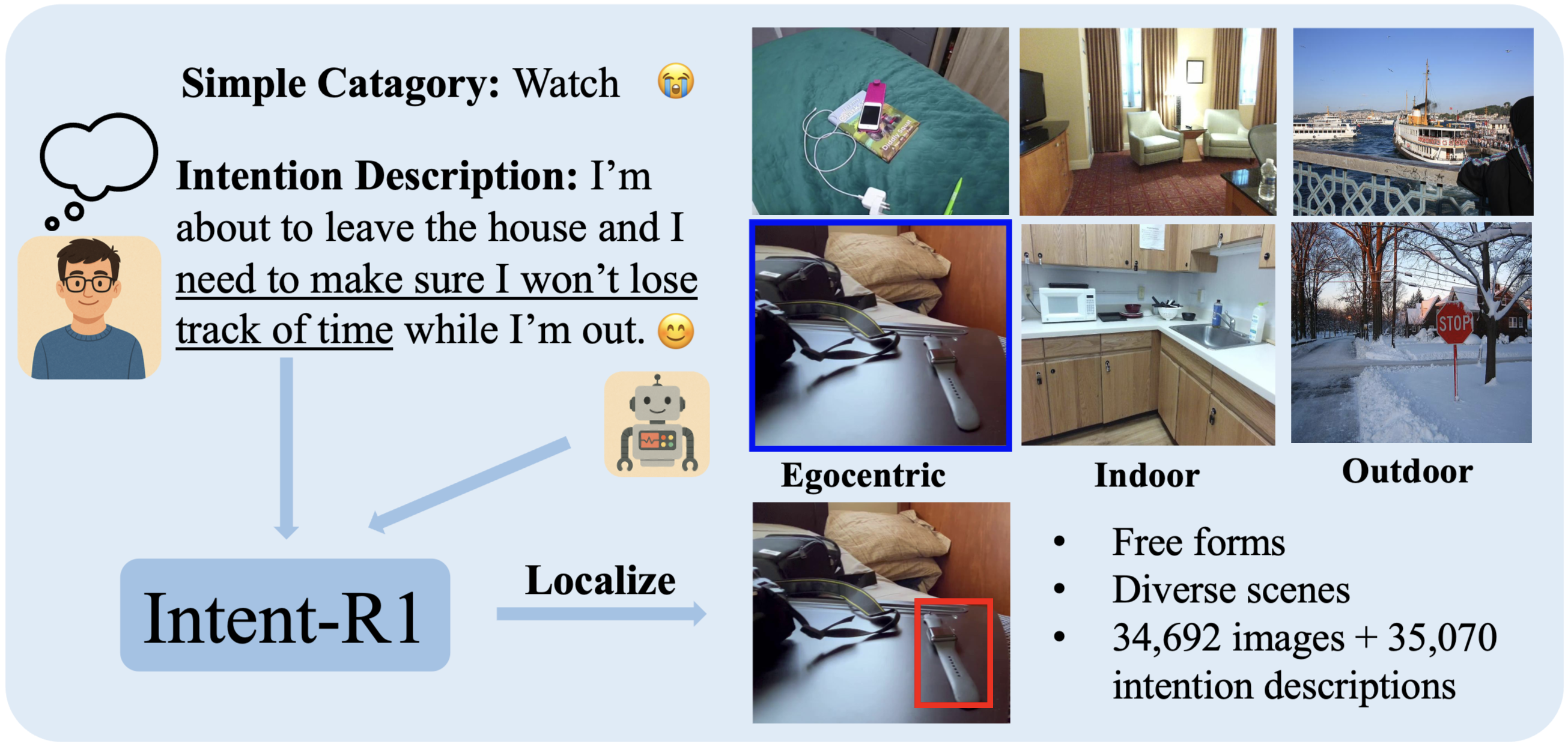
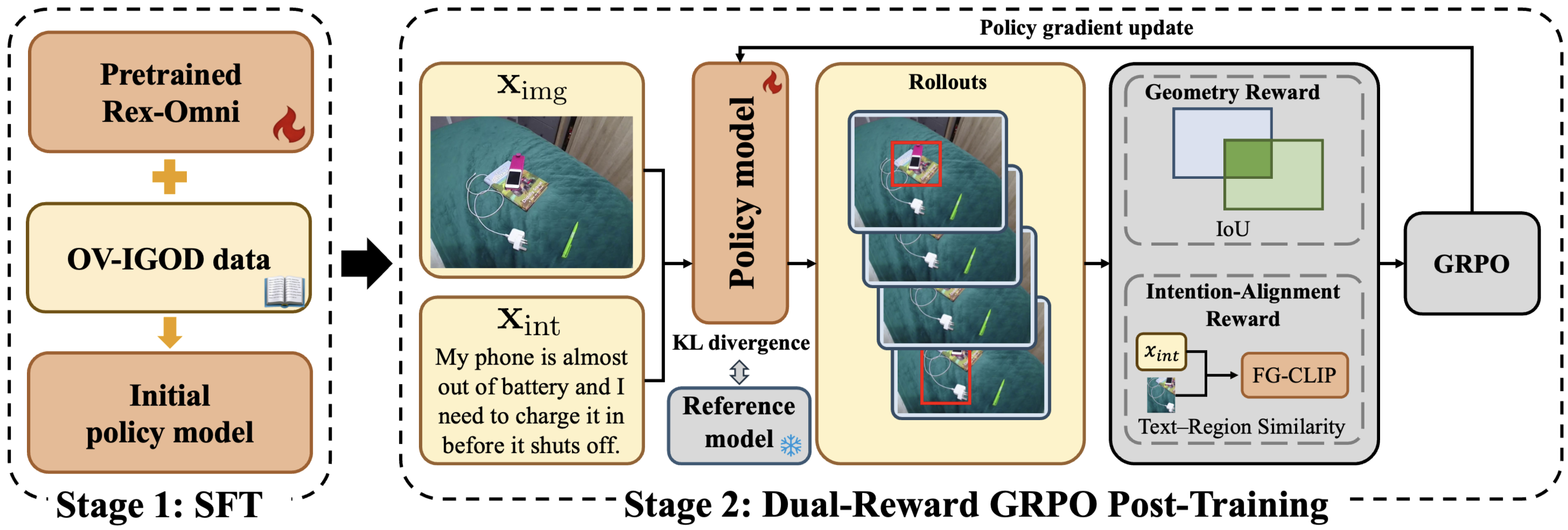
Accurately identifying and localizing objects that satisfy implicit user intentions remains a fundamental challenge for intelligent assistive systems. We present TriIntentBench, a large-scale benchmark for open-vocabulary intention-guided object detection with free-form, implicit intention descriptions and instance-level bounding-box annotations spanning egocentric, indoor third-person, and outdoor scenarios. We further propose Intent-R1, a two-stage post-training framework for pretrained vision-language models: supervised fine-tuning for task alignment, followed by dual-reward GRPO post-training that focuses updates on informative samples and jointly optimizes localization accuracy and intention-region consistency. Extensive experiments show robust generalization across all three scenario types, achieving mIoU of 64.12, 56.35, and 65.87 on egocentric, indoor, and outdoor subsets, respectively.